Hadoop 海量数据存储与计算的革命性解决方案
在当今大数据时代,企业和组织面临着前所未有的数据挑战。传统的数据处理系统已经难以应对PB级别的海量数据,而Hadoop作为开源分布式系统的杰出代表,为海量数据的存储和计算提供了革命性的解决方案。
Hadoop的核心架构与组件
Hadoop生态系统主要由两大核心组件构成:HDFS(Hadoop分布式文件系统)和MapReduce计算框架。
HDFS:可靠的数据存储基石
HDFS采用主从架构设计,由NameNode和DataNode组成。NameNode负责管理文件系统的元数据,而DataNode则存储实际的数据块。这种设计具有以下显著优势:
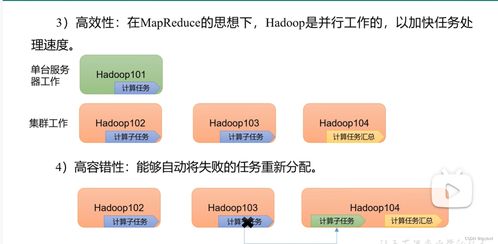
- 高容错性:数据自动复制到多个节点,单点故障不会导致数据丢失
- 高吞吐量:支持大规模数据集的并行读写操作
- 可扩展性:能够轻松扩展到数千个节点,存储EB级别的数据
- 成本效益:可在廉价的商用硬件上运行
MapReduce:高效的数据处理引擎
MapReduce采用"分而治之"的策略,将复杂的数据处理任务分解为两个阶段:
Map阶段:将输入数据分割成独立的块,由不同的节点并行处理
Reduce阶段:将Map阶段的输出进行汇总,生成最终结果
这种计算模型特别适合批处理任务,能够高效处理TB甚至PB级别的数据。
Hadoop的生态系统扩展
除了核心组件,Hadoop还拥有丰富的生态系统:
- HBase:分布式列式数据库,支持实时数据访问
- Hive:数据仓库工具,提供类SQL查询功能
- Pig:高级数据流语言,简化MapReduce编程
- Spark:内存计算框架,大幅提升处理速度
- ZooKeeper:分布式协调服务
Hadoop在行业中的应用
互联网行业
各大互联网公司使用Hadoop进行用户行为分析、推荐系统构建、日志处理等。例如,Facebook使用Hadoop集群存储超过100PB的数据,每天处理数PB的用户数据。
金融行业
银行和金融机构利用Hadoop进行风险控制、欺诈检测、客户画像分析,能够实时处理海量的交易数据。
电信行业
电信运营商使用Hadoop分析用户通话记录、网络流量数据,优化网络资源配置,提升服务质量。
Hadoop的技术优势
- 线性扩展能力:通过增加节点即可线性提升存储和计算能力
- 容错机制:自动处理节点故障,确保系统持续运行
- 数据本地化:计算任务尽可能在数据存储节点执行,减少网络传输
- 开源生态:活跃的社区支持和丰富的第三方工具
挑战与发展趋势
尽管Hadoop在大数据处理方面表现出色,但也面临一些挑战:
- 实时处理能力相对较弱
- 运维复杂度较高
- 对技能要求较高
Hadoop正朝着实时化、云原生、智能化方向发展,与容器技术、机器学习等新兴技术深度融合。
结语
Hadoop作为大数据技术的基石,已经证明了自己在处理海量数据方面的卓越能力。随着技术的不断演进,Hadoop必将在数字经济时代继续发挥关键作用,为各行各业的数据驱动决策提供强有力的支撑。对于任何需要处理大规模数据的企业来说,掌握和运用Hadoop技术已经成为必备的核心竞争力。
如若转载,请注明出处:http://www.nuchonglianmeng.com/product/27.html
更新时间:2026-06-19 00:04:21